## Overview and Goals
As a Machine Learning intern at [XRI Global](https://www.xriglobal.ai/), I researched and fine-tuned Automatic Speech Recognition models, focusing on the *least* spoken of the [Ethnologue top 200 most spoken languages list](https://www.ethnologue.com/insights/ethnologue200/).
Speaker distribution across languages is heavily concentrated among the top languages, with a steep decline moving down the ranks, followed by a long tail of languages with smaller speaker bases. The Ethnologue 200 counts both native and non-native speakers of languages. The data reveals that the top 100 languages are spoken by 9.63 billion people, while the next 100 are spoken by 786.7 million people. Out of the 200 most spoken languages (counting native and second language speakers), the top 100 represent 92% of the total whereas the next 100 is about 8%. I created the graph [here](https://aliklec.github.io/languages-chart.html) using the Ethnologue 200 data to show this distribution. Considering *native-speakers only*, Ethnologue [explains](https://www.ethnologue.com/insights/how-many-languages/) that the top 20 languages (just 0.3% of the world's 7000+ languages) are spoken natively by 3.7 billion people, almost 50% of the population. The concentration of speakers means that more resources, models, and data are available for the top languages.
The goal of my research project was to focus on the lowest-ranked languages within the top 200 to determine availability of open-source speech recognition models and datasets, and to fine-tune ASR models for those languages lacking dedicated, open-source speech recognition models.
Throughout the project, I attended weekly meetings with my advisor, reported on my findings, and translated complex results into accessible summaries. Taking direction from various stakeholders at XRI Global, I ensured my work remained aligned with company priorities and adjusted my approach based on ongoing feedback. It was also important to prepare clean, reproducible code, structured data spreadsheets, and concise written summaries for shared use, and to maintain organized file systems on shared drives so that others could easily access and build on my contributions.
## Initial Research on the ASR Landscape
I started researching available ASR data and models by searching ACL Anthology, Hugging Face, Papers with Code, Github, arXiv, and other sources. To keep track of my findings, I created a spreadsheet, reverse-ranking the Ethnologue 200, and added details for each language including dialects and alternate language names, ISO 639-3 code, available ASR models and data, licensing information, and whether large multilingual models like MMS, Whisper, and Xeus support the language.
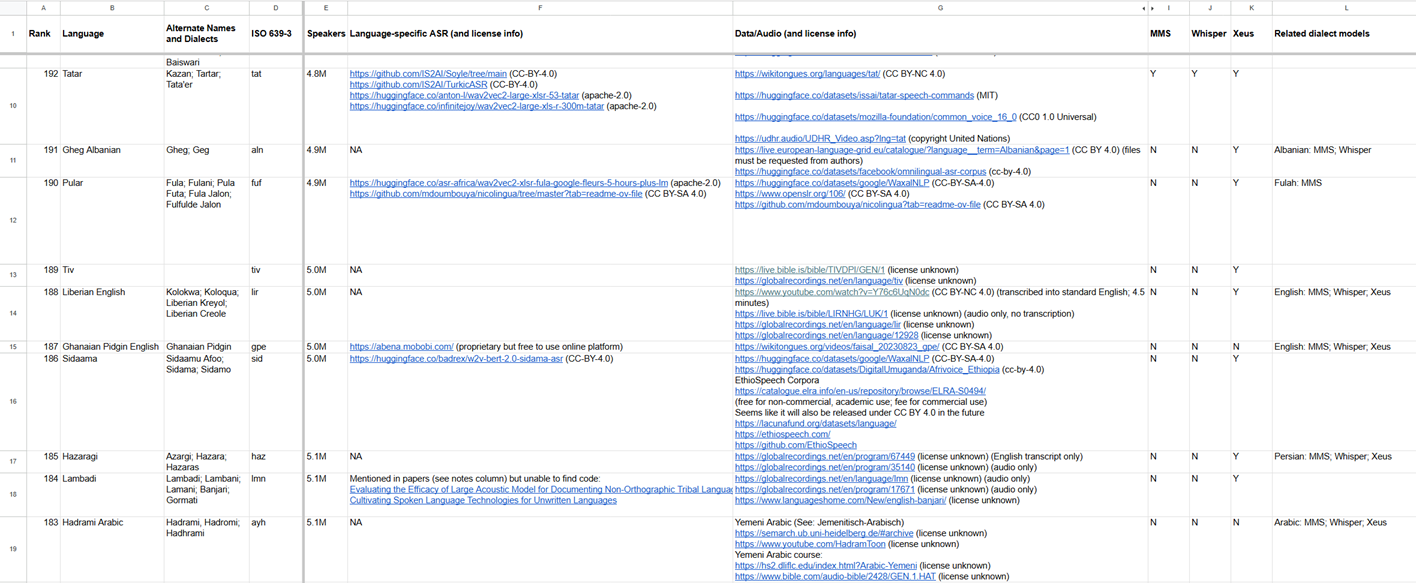
Several ASR models, such as MMS, Xeus, Omnilingual, and Whisper, claim broad language support, but this does not necessarily translate to strong performance on a given language or ease of use in practice. Xeus and Omnilingual proved difficult to run and use reliably (discussed further in the "Challenges" section), and OpenAI [reports](https://github.com/openai/whisper) WERs above 50% for Whisper Large on several languages, such as Swahili and Albanian. While I still tracked large multilingual model support in the spreadsheet, it did not rule out the need for a fine-tuned model.
In terms of data, I listed everything I came across, but the aim was to find data with open licenses such as [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/deed.en) or [Apache-2.0](https://www.apache.org/licenses/LICENSE-2.0) to be used for fine-tuning.
I also researched options for testing and benchmarking ASR models, as well as recipes for fine-tuning on speech data. One helpful resource was Hugging Face's 2022 [Whisper Fine-Tuning Event](https://github.com/huggingface/community-events/tree/main/whisper-fine-tuning-event) documentation and [fine-tuning guide](https://huggingface.co/blog/fine-tune-whisper). For MMS, [Fine-tuning MMS Adapter Models for Multi-Lingual ASR](https://huggingface.co/blog/mms_adapters) was another useful reference.
Out of the least spoken 50 languages in the Ethnologue list, I identified several with open source datasets that did not have dedicated, open source ASR models, meeting the criteria for fine-tuning candidates. The following are the languages and datasets I chose to focus on:
- **Kamba** - [Google FLEURS](https://huggingface.co/datasets/google/fleurs)
- **Minangkabau** - [SEACrowd Data Hub](https://github.com/SEACrowd)
- **Sicilian** - [Meta Omnilingual ASR Corpus](https://huggingface.co/datasets/facebook/omnilingual-asr-corpus)
- **Gheg Albanian** - [Meta Omnilingual ASR Corpus](https://huggingface.co/datasets/facebook/omnilingual-asr-corpus)
I primarily worked with Whisper as the base model due to it having the best fine-tuning results, clearest recipes, and being most accessible, though I did experiment with other models.
## Fine-Tuning Process
#### Tools and Libraries Used
For my fine-tuning research, I used Python and worked in Google Colab Pro with an A100 GPU.
The main libraries and tools I used for Whisper fine-tuning were:
- `datasets` (Hugging Face): downloading and managing speech datasets
- `DatasetDict`: organizing dataset splits
- `load_dataset`: retrieving data from Hugging Face Hub
- `Audio`: casting audio columns and resampling
- `transformers` (Hugging Face): core library providing Whisper components
- `WhisperFeatureExtractor`: converting audio to log-Mel spectrograms
- `WhisperTokenizer`: encoding and decoding text tokens
- `WhisperForConditionalGeneration`: loading pretrained Whisper model for fine-tuning
- `DataCollatorSpeechSeq2SeqWithPadding`: preparing PyTorch tensors with proper padding
- `Seq2SeqTrainer` and `Seq2SeqTrainingArguments`: configuring and running training loop
- `torch` (PyTorch) tensor operations
- `evaluate / jiwer`: computing Word Error Rate (WER)
#### Data Exploration and Preprocessing
Many of the speech datasets available on Hugging Face are in good shape overall. However, some preprocessing steps were still required to prepare the data for fine-tuning. Below I will walk through my fine-tuning steps using Omnilingual's Sicilian data as an example. Printing a sample from the dataset reveals several elements that needed to be addressed before training. Below we can see that the segment is over 76 seconds long, the sampling rate is 48,000 Hz, and the transcription contains a mix of punctuation, capitalization, and newline characters:
```
{'language': 'scn_Latn', 'speaker_id': 'spk01', 'prompt_id': 'a001', 'prompt': 'How much exercise does a dog need daily?', 'segment_id': 's01', 'audio': {'path': 'spk01_a001_s01.flac', 'array': array([ 9.15527344e-05, 1.52587891e-04, 6.10351562e-05, ...,
-1.64794922e-03, -1.73950195e-03, -1.86157227e-03]), 'sampling_rate': 48000}, 'duration': 76.60825, 'raw_text': "Allura... Quantu eserciziu avissi a fari un cani ogni jornu? \nSinceramenti nun haiu idea, 'un haiu mai avutu un cani. \nPerò pozzu arrispùnniri pinsannu a chiddu ca vitti fari ad àutri... generalmenti si senti sempri ca lu cani havi bisognu di fari la so passiata cutidiana ca è o na passiata o è pi iddu fari li so' affari, li bisogni. \nNun lu sacciu. \n'N tiurìa sunnu tutti dui li cosi, a cui pensu quannu taliu li pillìculi o àutri cchiù o menu sempri ddà. \nPi quantu riguarda l'eserciziu, supponemu ca na caminata avissi a durari almenu deci minuti forsi venti minuti e quinni pozzu suppòniri chi chista è la quantità mìnima c'avissi a fari nu cani ogni jornu... multiplicatu pi lu nùmeru di bisogni... Un'ura di eserciziu macari macari... lu cani chiaramenti si movi puru nt casa. \nNun si tratta sulu di attività esterni. \nAllura non lu sacciu chiù, supponemu ca na passiata di un'ura è lo sporti minimu, si appressu si pò fari n'àutra, di chiù mègghiu ancora.", 'iso_639_3': 'scn', 'glottocode': 'sici1248', 'iso_15924': 'Latn'}
```
Whisper was designed to process audio in 30-second segments and anything longer is truncated. Trimmed audio would create a mismatch with the reference transcription and could introduce hallucinations and incorrect transcriptions. To deal with the length issue, I filtered out segments longer than 30 seconds using the code below. The original Sicilian dataset has about 9 hours of speech data, of which approximately 5 hours remained after filtering.
```
scn = scn.filter(lambda x: x["duration"] <= 30.0)
```
Another preprocessing step involved ensuring each audio segment was resampled to match the correct input format. Whisper expects audio at a rate of 16,000 samples per second. Using a different rate would distort how the audio is interpreted by the model, leading to poor transcription results. To address this, I used `cast_column` (a Hugging Face method that resamples audio on the fly) to convert the Sicilian data sampling rate:
```
from datasets import Audio
scn = scn.cast_column("audio", Audio(sampling_rate=16000))
```
There were also decisions to make about text normalization, which can have a significant impact on WER calculations. To illustrate, computing WER for "`electronic engineer`" against "`Electronic engineer.`" returns a score of 1.0, a 100% error rate, because the capital letter and period cause the words to be treated as different. Although ASR systems that can accurately predict punctuation are useful, normalizing text is standard practice for WER evaluation. Both Whisper and MMS report normalized WER in their published results, and many datasets provide already-normalized transcriptions. For consistent comparison, I normalized the Sicilian data as well. Below is a sample transcript before and after applying the Whisper normalizer:
```
from whisper_normalizer.basic import BasicTextNormalizer
normalizer = BasicTextNormalizer()
sentence = "Allura... Quantu eserciziu avissi a fari un cani ogni jornu? \nSinceramenti nun haiu idea, 'un haiu mai avutu un cani. \nPerò pozzu arrispùnniri pinsannu a chiddu ca vitti fari ad àutri... generalmenti si senti sempri ca lu cani havi bisognu di fari la so passiata cutidiana ca è o na passiata o è pi iddu fari li so' affari, li bisogni. \nNun lu sacciu."
normalized = normalizer(sentence)
print("Original: ",repr(sentence),"\n")
print("Normalized: ",normalized)
Original: Allura... Quantu eserciziu avissi a fari un cani ogni jornu? \nSinceramenti nun haiu idea, 'un haiu mai avutu un cani. \nPerò pozzu arrispùnniri pinsannu a chiddu ca vitti fari ad àutri... generalmenti si senti sempri ca lu cani havi bisognu di fari la so passiata cutidiana ca è o na passiata o è pi iddu fari li so' affari, li bisogni. \nNun lu sacciu.
Normalized: allura quantu eserciziu avissi a fari un cani ogni jornu sinceramenti nun haiu idea un haiu mai avutu un cani però pozzu arrispùnniri pinsannu a chiddu ca vitti fari ad àutri generalmenti si senti sempri ca lu cani havi bisognu di fari la so passiata cutidiana ca è o na passiata o è pi iddu fari li so affari li bisogni nun lu sacciu
```
Working with low-resource languages often calls for strategies to maximize the limited amount of data, so in some cases, I also chose to combine training and development data to increase the number of training examples, using the Hugging Face `datasets` library:
```
from datasets import concatenate_datasets
combined_train = concatenate_datasets([scn['train'], scn['validation']])
kamba['train'] = combined_train
```
#### Feature Extractor and Tokenizer
After data loading and preprocessing, the next step was to configure the feature extractor and tokenizer. Whisper's feature extractor transforms raw audio into log-mel spectrograms. As covered in my Speech Technology class, the mel scale approximates how humans perceive pitch, emphasizing the frequency ranges most useful for distinguishing speech sounds, which makes it a good fit for speech recognition. The feature extractor also ensures each audio segment is padded or shortened to 30 seconds, as required by the Whisper model.
The tokenizer handles the text side of the pipeline, mapping reference transcriptions to token IDs during training and then back to text during inference. When fine-tuning on languages not directly supported by Whisper, it is important to select the most closely related base language available. This helps the model learn more effectively due to shared sound patterns, structure, and spelling conventions. Based on linguistic proximity, I made the following choices for each of the languages I worked with:
| Fine-Tuning Language | Base Language |
|----------------------|---------------|
| Gheg Albanian | Albanian |
| Kamba | Swahili |
| Minangkabau | Malay |
| Sicilian | Italian |
The feature extractor and tokenizer were then loaded as follows with the chosen base language:
```
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
from transformers import WhisperTokenizer
tokenizer = WhisperTokenizer.from_pretrained("openai/whisper-small", language="italian", task="transcribe")
```
#### Preparing the Dataset
With the feature extractor and tokenizer configured, I applied them to the dataset using the function below, which converts the raw audio into log-mel spectrograms and the reference transcriptions into token IDs:
```
def prepare_dataset(batch):
# load data
audio = batch["audio"]
# convert raw audio to log-mel spectrogram
batch["input_features"] = feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"]).input_features[0]
# convert transcription to token IDs
batch["labels"] = tokenizer(batch["text"]).input_ids
return batch
```
Then I mapped the function across the dataset, removing the original columns, leaving only `input_features` and `labels`:
```
scn = scn.map(prepare_dataset, remove_columns=min.column_names)
```
#### Loading and Configuring the Pre-Trained Model
The pre-trained Whisper model also needed to be configured with the related base language to ensure tokenizer consistency and to provide the most linguistically similar starting point for decoding:
```
from transformers import WhisperForConditionalGeneration
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small")
model.generation_config.language = "italian"
model.generation_config.task = "transcribe"
model.generation_config.forced_decoder_ids = None
```
#### Defining the Data Collator
After loading and configuring the model, the next step was defining and initializing the data collator. PyTorch tensors require everything in a batch to be the same size. The data collator is used to make sure that the tokenized transcription sequences, which vary in length, are padded to the same length so they can be converted to tensors. It also replaces padding tokens with -100, a special value in PyTorch that tells the model to ignore those positions so it only trains on actual data. The data collator also checks if a start token was already added to the beginning of each transcription, and removes it if so, since the model will add the start token back on later. The implementation I used for fine-tuning is shown below:
```
import torch
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class DataCollatorSpeechSeq2SeqWithPadding:
feature_extractor: Any
tokenizer: Any
decoder_start_token_id: int
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels to deal with them differently
input_features = [{"input_features": feature["input_features"]} for feature in features]
# convert audio features to tensors (already same length)
batch = self.feature_extractor.pad(input_features, return_tensors="pt")
# pad transcription labels to the same length and convert to tensors
label_features = [{"input_ids": feature["labels"]} for feature in features]
labels_batch = self.tokenizer.pad(label_features, return_tensors="pt")
# replace padding tokens with -100 so they are ignored during training
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
# remove start token if it was added during tokenization (it gets added again later)
if (labels[:, 0] == self.decoder_start_token_id).all().cpu().item():
labels = labels[:, 1:]
batch["labels"] = labels
return batch
#initialize
data_collator = DataCollatorSpeechSeq2SeqWithPadding(
feature_extractor=feature_extractor,
tokenizer=tokenizer,
decoder_start_token_id=model.config.decoder_start_token_id,
)
```
#### Evaluation
For evaluation, I used Word Error Rate (WER) as the primary metric. WER is reported by both Whisper and MMS in their published results and was the more commonly used measure across the ASR research I reviewed. Generally, WER gives a more meaningful sense of transcription accuracy for languages where words are separated by spaces. For example, transcribing `vest` as `best` would score well under CER since only one character differs, but WER considers them completely different words, which better reflects the change in meaning. That said, CER is more appropriate for character-based languages, and I did use it in some runs to compare against the Omnilingual ASR model, [which reports its results using CER](https://github.com/facebookresearch/omnilingual-asr/blob/main/per_language_results_table_7B_llm_asr.csv).
The function below shows the WER computation I used during training. It replaces the -100 values with the pad token ID so they can be decoded, then converts both predictions and labels back to text before calculating the score:
```
import evaluate
metric = evaluate.load("wer")
def compute_metrics(pred):
pred_ids = pred.predictions
label_ids = pred.label_ids
# replace -100 with the pad_token_id
label_ids[label_ids == -100] = tokenizer.pad_token_id
pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
label_str = tokenizer.batch_decode(label_ids, skip_special_tokens=True)
wer = 100 * metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
```
#### Configuring and Running Training
The final step was to configure the training arguments and launch fine-tuning. Below is a typical configuration I used, with a batch size of 16, a learning rate of 1e-5, and 5,000 training steps. For training, I used Hugging Face's `Seq2SeqTrainer`, which takes care of running training, evaluating the model, and saving checkpoints. Setting `predict_with_generate` to `True` ensures that during evaluation, the model generates full transcriptions. WER needs to compare whole sentences, and without this parameter, the model would only output raw token probabilities rather than an actual transcription to evaluate.
```
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="./whisper-small-min",
per_device_train_batch_size=16,
learning_rate=1e-5,
max_steps=5000,
fp16=True,
eval_strategy="steps",
eval_steps=1000,
predict_with_generate=True,
generation_max_length=225,
save_steps=1000,
load_best_model_at_end=True,
metric_for_best_model="wer",
greater_is_better=False,
)
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=scn["train"],
eval_dataset=scn["test"],
data_collator=data_collator,
compute_metrics=compute_metrics,
processing_class=feature_extractor,
tokenizer=tokenizer,
)
trainer.train()
```
## Results
Using the methods described above, I was able to improve transcription accuracy across all four languages. To measure the impact of fine-tuning, I established WER baselines for each language by running the original Whisper Small model on the same test data, using the same base language and configuration settings. My results and notes are summarized in the table below:
| | Kamba | Sicilian | Minangkabau | Gheg Albanian |
| -------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------- |
| **Speakers** | 5.3M | 4.7M | 5.6M | 4.7M |
| **Dataset** | Fleurs | Omnilingual | SEACrowd | Omnilingual |
| **License** | CC-BY-4.0 | CC-BY-4.0 | Apache-2.0 | CC-BY-4.0 |
| **Training Data** | 16 hours | 5 hours | 30 minutes | 3.4 hours |
| **Base Language used for Fine-Tuning** | Swahili | Italian | Malay | Albanian |
| **Baseline Comparison WER (Whisper Small)** | 123% | 75% | 77% | 97% |
| **Best Fine-Tuned WER (Whisper Small)** | 52% | 35% | 14% | 49% |
| **WER Reduction** | 58% | 53% | 82% | 49% |
| **Other Experiments / Considerations for Results** | BULLETS_KAMBA | BULLETS_SICILIAN | BULLETS_MINANGKABAU | BULLETS_GHEG |
## Challenges
The most obvious challenge inherent in working with low-resource languages is the limited amount of data available. In some cases, the datasets I used were extremely small, raising concerns about overfitting and generalizability. The Minangkabau dataset, for example, consisted of only about 30 minutes of audio from a single speaker reading the Universal Declaration of Human Rights. While the fine-tuned model achieved a low WER, it is difficult to know how well it would generalize to other speakers, settings, or recording conditions, and I was unable to find additional datasets for this language to test against.
A related challenge was adapting the available data to fit specific model requirements. The Omnilingual dataset contains many segments longer than 30 seconds, which I filtered out since Whisper processes audio in 30-second chunks. Though filtering proved to be the most practical solution, it would be more useful for low-resource languages to be able to easily split longer segments and realign them with the transcript in order to retain more training data. However, this is difficult to do correctly in practice and is something that warrants further research.
On the technical side, I ran into backward compatibility issues with the Hugging Face `datasets` library. Updates to the library caused conflicts with older datasets, and after searching the Hugging Face forums I found a [solution](https://github.com/huggingface/datasets/issues/7693) that involved downgrading to version 3.6.0 to use `load_dataset` reliably. I also encountered errors related to backpropagation through the computation graph, as well as floating point precision issues during training, both of which required additional debugging.
Working with some of the large multilingual ASR models proved difficult despite their claimed support for many languages. XEUS, for example, presents itself as covering over 4,000 languages, but it is a speech encoder rather than a full transcription system, meaning it requires additional fine-tuning to be used for speech recognition. It also lacks a stable, easily accessible codebase, making it impractical to work with for this research. The Omnilingual ASR model required significant effort to set up due to dependency issues, and I ultimately had to clone and run it locally, referencing a [GitHub repo from Abu Anas Shuvom](https://github.com/xhuvom/omnilingual-ASR-Web-Dashboard) that helped address compatibility issues. Whisper was by far the easiest to work with, but ideally all models would be simple to use, both for research comparison purposes and for the wider goal of making low-resource language models more accessible.
Another challenge was the lack of transparency and reproducibility across published ASR research. Papers do not always share how data was processed, what was included in training and validation sets, or what configuration choices were made, making comparisons difficult. The 680,000 hours of data used to train Whisper are not open source, so it is not possible to understand how this may have influenced performance on specific languages. This makes it harder to draw meaningful conclusions about why one model outperforms another on a given language.
## Future Work
In future research, I would like to further investigate and experiment with Parameter-Efficient Fine-Tuning (PEFT), specifically Low-Rank Adaptation (LoRA). While LoRA made fine-tuning significantly faster and more efficient, I was unable to achieve better WER results compared to full fine-tuning. Some research I came across suggested that LoRA can help with overfitting and in some cases even improve performance. In my experiments, LoRA produced reasonable WER scores but still fell short of full fine-tuning. Testing different LoRA configurations could potentially yield better results, so this is something I would like to explore further.
I would also like to further investigate audio segmentation and alignment as a way to recover more training data. As mentioned previously, many of the segments in the Omnilingual dataset are longer than 30 seconds. I did some experimentation with splitting longer segments and attempting to realign them with the transcript, but this led to discrepancies between the audio and transcriptions. This would be worth revisiting given the potential to retain more data for training.
Being able to further test the Minangkabau results is another future goal. With only about 30 minutes of single-speaker audio, it is unclear whether the model is overfitting to that specific speaker, context, and recording setup. While I did run a couple of informal tests on Minangkabau Wikitongues recordings and YouTube clips as a proof of concept and the transcriptions appeared fairly accurate, this is not the same as evaluating on a full and diverse speech dataset.
Taking part in this research has given me the opportunity to work on a problem with real-world implications. The work I conducted will contribute to XRI's ongoing efforts to improve transcription capabilities for low-resource languages on XRIstudio.ai, helping to close the gap in transcription quality for speakers of underserved languages.
## References
Chen, W., et al. (2024). Towards Robust Speech Representation Learning for Thousands of Languages. [https://arxiv.org/pdf/2407.00837](https://arxiv.org/pdf/2407.00837)
Dash, B. M. (2024). Fine-tuning Whisper to learn my mother tongue ODIA. YouTube. [https://www.youtube.com/watch?v=lNj7RkOms2U](https://www.youtube.com/watch?v=lNj7RkOms2U)
Gambo, E. (2025). Fine-tuning Whisper for Kildin Sami, a low-resource endangered language. https://erepo.uef.fi/server/api/core/bitstreams/99413d95-a2bd-477a-a819-e60d152473af/content
Gandhi, S. (2022). Fine-tune Whisper for multilingual ASR with 🤗 Transformers. Hugging Face Blog. [https://huggingface.co/blog/fine-tune-whisper](https://huggingface.co/blog/fine-tune-whisper)
Ghimire, R. R., et al. (2024). Improving on the limitations of the ASR model in low-resourced environments using parameter-efficient fine-tuning. [https://aclanthology.org/2024.icon-1.47.pdf](https://aclanthology.org/2024.icon-1.47.pdf)
Islam, S. M. J. (2024). Quickstart finetuning large ASR models using LoRA. [https://www.kaggle.com/code/smjishanulislam/quickstart-finetuning-large-asr-models-using-lora](https://www.kaggle.com/code/smjishanulislam/quickstart-finetuning-large-asr-models-using-lora)
Liu, Y., et al. (2024). Exploration of Whisper fine-tuning strategies for low-resource ASR. [https://doi.org/10.1186/s13636-024-00349-3](https://doi.org/10.1186/s13636-024-00349-3)
Prakash, S. (2024). LoRA for fine-tuning LLMs. [https://medium.com/@shwet.prakash97/lora-for-finetuning-llms-5810f7fab8a2](https://medium.com/@shwet.prakash97/lora-for-finetuning-llms-5810f7fab8a2)
Pratap, V., et al. (2023). Scaling Speech Technology to 1,000+ Languages. [https://arxiv.org/pdf/2305.13516](https://arxiv.org/pdf/2305.13516)
Radford, A., et al. (2022). Robust Speech Recognition via Large-Scale Weak Supervision. https://cdn.openai.com/papers/whisper.pdf
Sharma, A. K., et al. (2025). Fine-tuning Whisper Tiny for Swahili ASR: Challenges and recommendations for low-resource speech recognition. [https://aclanthology.org/2025.africanlp-1.11.pdf](https://aclanthology.org/2025.africanlp-1.11.pdf)